
对抗搜索复习
MiniMax算法
- 有两个玩家Max和Min,假设这两个玩家都铁分奴,不会假赛。
- Min的战略
- 想要分数尽可能地最低,最好是。
- 也必须考虑到Max会尽可能地让分数高,最坏是。
- Min的最佳策略是:选择使Max得分最高的移动时所得分数最小化的移动。
- Max的战略和Min相反
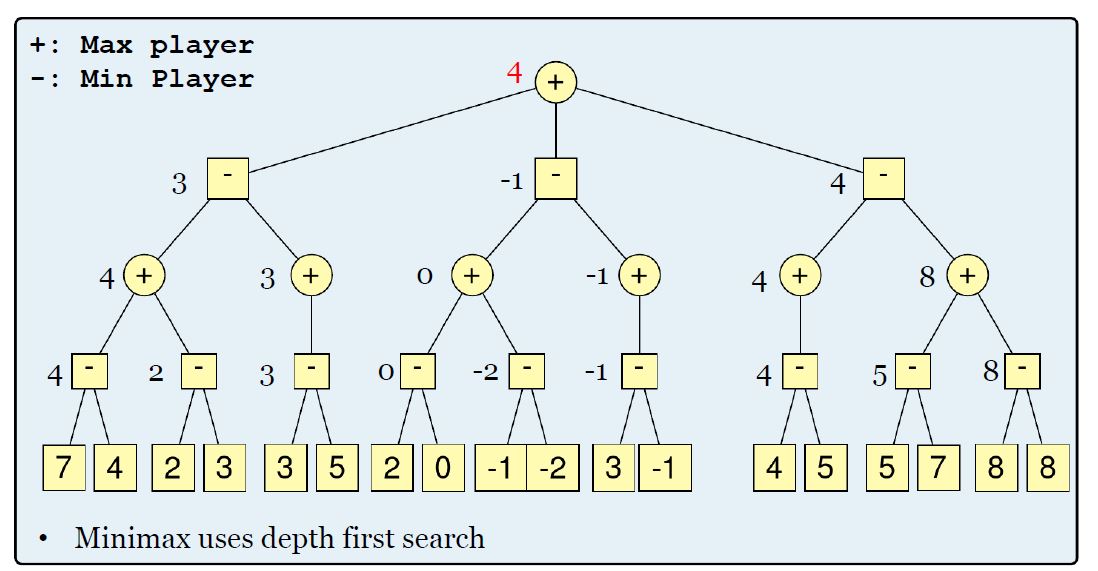
MiniMax算法的弊端
- MiniMax算法使用DFS算法,空间复杂度是,时间复杂度是,空间复杂度是,要搜索的点太多了。
- 其实并不需要知道每个节点需要选择的值具体是多少。
- 可以使用a-b剪枝来去除多余的点。
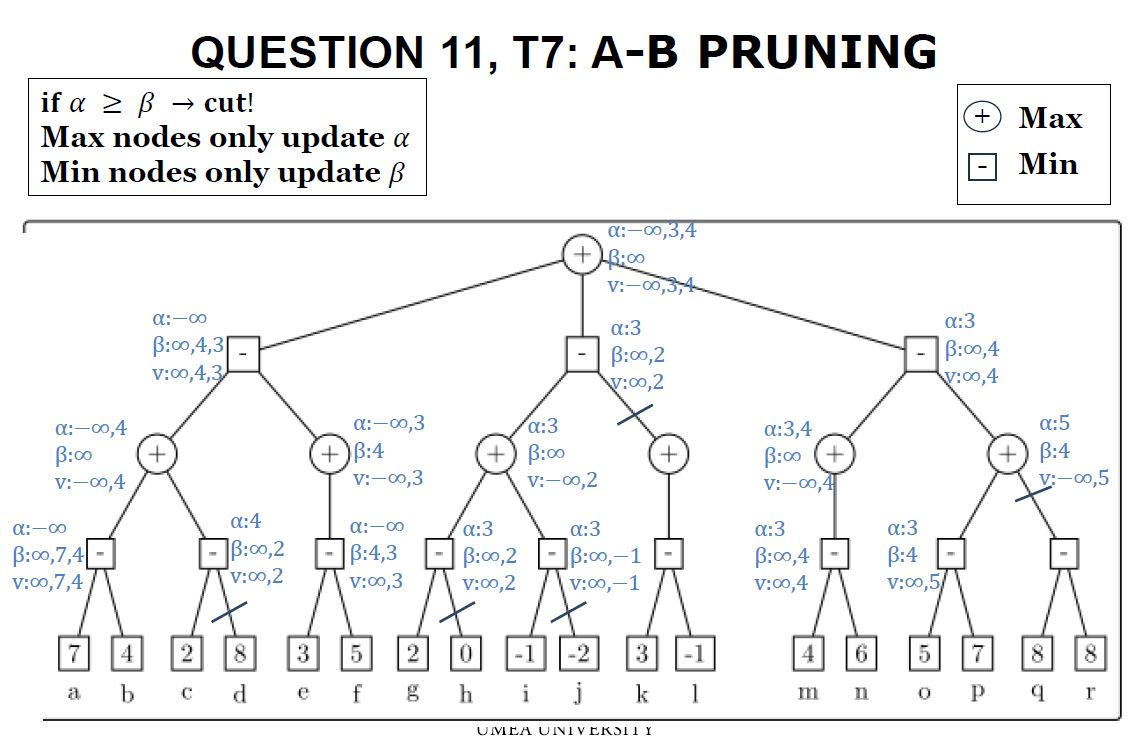
alpha-beta 剪枝
-
Alpha:到目前为止,在路径上找到的对于Max来说的最好(最高)值。
也就是说,对于Max,的值越高越好。
的值是实际结果的下限。
-
Beta:到目前为止,在路径上找到的对于Min来说的最好(最低)值。
也就是说,对于Min,的值越高越好。
的值是实际结果的上限。
-
a-b剪枝的伪代码是:

a-b剪枝的练习
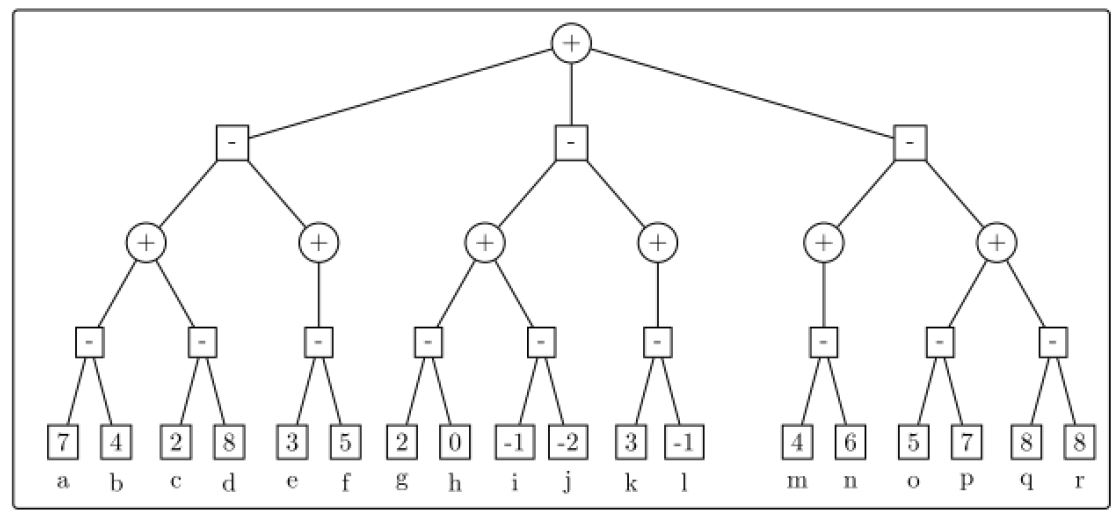
有如图所示的树,那么如何应用a-b剪枝呢? 按照伪代码执行一遍:
答案:
ALPHA-BETA VS. MINIMAX
MiniMax需要访问O()个点。
Alpha Beta访问多少节点取决于检查移动的顺序。(比如A节点下面有a,b,c三个子节点,如果直接访问c几点,可以cut-off。但必须按照顺序访问a和b,这样就浪费时间了。)
- 最好的情况下:访问个点
- 随机移动顺序下:访问个点
我们可以使用特定领域的知识来实现合理的移动顺序。
对于国际象棋来说,有可能合理地接近最好的情况。
搜索截断
- 不能让Alpha Beta搜索整个游戏树(这对于国际象棋来说是不现实的),我们应该希望中断搜索并返回一个启发式评估。
- 一个简单的方法:设置搜索深度(需要确保,在当前深度下多搜索一层也可以在时间限制内完成。)
- 更有鲁棒性的方法:使用IDS迭代深度搜索。
- 从深度1开始,使用ab算法,返回一个结果,并储存。然后从深度2开始,循环。
- 当时间到了,返回最深次完成的移动结果。
- 额外的:人工的修改移动顺序。
- 仅为搜索呈指数增长的树添加固定时间
增加动态行棋排序方案,如先试图采用以前走过的最好行棋,可能让我们非常接近理论极限。以前的行棋可能是上一步棋—— 面临同样的棋局威胁—— 也可能来自当前行棋的上一次搜索过程。
从当前行棋获得信息的一种方法是迭代深入搜索。首先,搜索一层并记录最好行棋路径。接着搜索更深一层,此时使用记录的路径来导引行棋排序。最好行棋称为绝招,先走绝招称为绝招启发式。
静态搜索
假设程序在搜索棋局时到达了深度限制,此时黑方有一马两兵的优势。程序会报告这个状态的启发式函数值,从而认为这个状态会导致黑方获胜。
而其实下一步白方就可以毫无意外地吃掉黑方皇后。因此,这个棋局实际是白棋赢,需要向前多看一步才能预测。
这个时候就要应用静态搜索。我们应该只停留在“好”的位置,这个位置不太可能在不久的将来造成价值的剧烈波动(例如不要在可以吃对面子的情况下停下来)。
向前剪枝
除了截断搜索,还可以进行正向修剪;立即删掉一些动作!(就像人类一样,通常只考虑一些动作,而考虑不到全局。)
- 为此,我们可以使用波束搜索- 只考虑N个最佳动作的一个“波束”(根据评估函数)
- 尽管如此,我们不能保证最好的举措不会被取消!-可采用统计或概率方法降低风险
启发式的设计
- 游戏搜索的启发式功能通常结合了许多功能
- 得出值的一种方法是使用统计数据
例如:在我数据库中所有与当前位置状态的完全相同的位置中,有多少最终被白棋赢得? 如果这个数字是,比如说75%,我们可以返回值0.5(其中1是白赢,-1是黑赢) - 此方法也可用于构建开放式数据库。
总结
a-b剪枝算法的本质是一种对树的搜索的递归。
设计一个带AI下棋的小游戏,需要拥有:
- Alpha-Beta搜索。
- 移动排序:绝招优先,带截断的IDS搜索。
- 换位表:查看该状态是否已经出现过了,避免重复访问。
- 好的启发式
- 静态搜索
- 开局数据库
- 残局数据库
- 有效的棋盘表示
参考
[1]StuartJ.Russell, PeterNorvig, 诺维格,等. 人工智能:一种现代的方法[J]. 清华大学出版社, 2013.




